Engine Configuration¶
The Engine is the starting point for any SQLAlchemy application. It’s
“home base” for the actual database and its DBAPI, delivered to the SQLAlchemy
application through a connection pool and a Dialect, which describes how
to talk to a specific kind of database/DBAPI combination.
The general structure can be illustrated as follows:
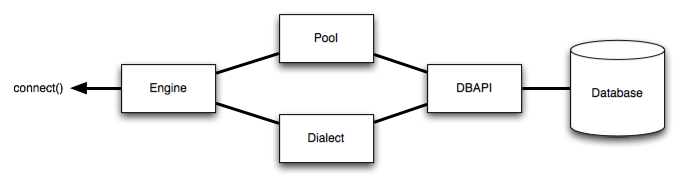
Where above, an Engine references both a
Dialect and a Pool,
which together interpret the DBAPI’s module functions as well as the behavior
of the database.
Creating an engine is just a matter of issuing a single call,
create_engine():
from sqlalchemy import create_engine
engine = create_engine("postgresql+psycopg2://scott:tiger@localhost:5432/mydatabase")The above engine creates a Dialect object tailored towards
PostgreSQL, as well as a Pool object which will establish a
DBAPI connection at localhost:5432 when a connection request is first
received. Note that the Engine and its underlying
Pool do not establish the first actual DBAPI connection
until the Engine.connect() or Engine.begin()
methods are called. Either of these methods may also be invoked by other
SQLAlchemy Engine dependent objects such as the ORM
Session object when they first require database connectivity.
In this way, Engine and Pool can be said to
have a lazy initialization behavior.
The Engine, once created, can either be used directly to interact with the database,
or can be passed to a Session object to work with the ORM. This section
covers the details of configuring an Engine. The next section, Working with Engines and Connections,
will detail the usage API of the Engine and similar, typically for non-ORM
applications.
Supported Databases¶
SQLAlchemy includes many Dialect implementations for various
backends. Dialects for the most common databases are included with SQLAlchemy; a handful
of others require an additional install of a separate dialect.
See the section Dialects for information on the various backends available.
Database URLs¶
The create_engine() function produces an Engine
object based on a URL. The format of the URL generally follows RFC-1738, with some exceptions, including that
underscores, not dashes or periods, are accepted within the “scheme” portion.
URLs typically include username, password, hostname, database name fields, as
well as optional keyword arguments for additional configuration. In some cases
a file path is accepted, and in others a “data source name” replaces the “host”
and “database” portions. The typical form of a database URL is:
dialect+driver://username:password@host:port/databaseDialect names include the identifying name of the SQLAlchemy dialect,
a name such as sqlite, mysql, postgresql, oracle, or mssql.
The drivername is the name of the DBAPI to be used to connect to
the database using all lowercase letters. If not specified, a “default” DBAPI
will be imported if available - this default is typically the most widely
known driver available for that backend.
Escaping Special Characters such as @ signs in Passwords¶
When constructing a fully formed URL string to pass to
create_engine(), special characters such as those that may
be used in the user and password need to be URL encoded to be parsed correctly..
This includes the @ sign.
Below is an example of a URL that includes the password "kx@jj5/g", where the
“at” sign and slash characters are represented as %40 and %2F,
respectively:
postgresql+pg8000://dbuser:kx%40jj5%2Fg@pghost10/appdbThe encoding for the above password can be generated using urllib.parse:
>>> import urllib.parse
>>> urllib.parse.quote_plus("kx@jj5/g")
'kx%40jj5%2Fg'The URL may then be passed as a string to create_engine():
from sqlalchemy import create_engine
engine = create_engine("postgresql+pg8000://dbuser:kx%40jj5%2Fg@pghost10/appdb")As an alternative to escaping special characters in order to create a complete
URL string, the object passed to create_engine() may instead be an
instance of the URL object, which bypasses the parsing
phase and can accommodate for unescaped strings directly. See the next
section for an example.
Changed in version 1.4: Support for @ signs in hostnames and database names has been
fixed. As a side effect of this fix, @ signs in passwords must be
escaped.
Creating URLs Programmatically¶
The value passed to create_engine() may be an instance of
URL, instead of a plain string, which bypasses the need for string
parsing to be used, and therefore does not need an escaped URL string to be
provided.
The URL object is created using the URL.create()
constructor method, passing all fields individually. Special characters
such as those within passwords may be passed without any modification:
from sqlalchemy import URL
url_object = URL.create(
"postgresql+pg8000",
username="dbuser",
password="kx@jj5/g", # plain (unescaped) text
host="pghost10",
database="appdb",
)The constructed URL object may then be passed directly to
create_engine() in place of a string argument:
from sqlalchemy import create_engine
engine = create_engine(url_object)Backend-Specific URLs¶
Examples for common connection styles follow below. For a full index of detailed information on all included dialects as well as links to third-party dialects, see Dialects.
PostgreSQL¶
The PostgreSQL dialect uses psycopg2 as the default DBAPI. Other PostgreSQL DBAPIs include pg8000 and asyncpg:
# default
engine = create_engine("postgresql://scott:tiger@localhost/mydatabase")
# psycopg2
engine = create_engine("postgresql+psycopg2://scott:tiger@localhost/mydatabase")
# pg8000
engine = create_engine("postgresql+pg8000://scott:tiger@localhost/mydatabase")More notes on connecting to PostgreSQL at PostgreSQL.
MySQL¶
The MySQL dialect uses mysqlclient as the default DBAPI. There are other MySQL DBAPIs available, including PyMySQL:
# default
engine = create_engine("mysql://scott:tiger@localhost/foo")
# mysqlclient (a maintained fork of MySQL-Python)
engine = create_engine("mysql+mysqldb://scott:tiger@localhost/foo")
# PyMySQL
engine = create_engine("mysql+pymysql://scott:tiger@localhost/foo")More notes on connecting to MySQL at MySQL and MariaDB.
Oracle¶
The Oracle dialect uses cx_oracle as the default DBAPI:
engine = create_engine("oracle://scott:tiger@127.0.0.1:1521/sidname")
engine = create_engine("oracle+cx_oracle://scott:tiger@tnsname")More notes on connecting to Oracle at Oracle.
Microsoft SQL Server¶
The SQL Server dialect uses pyodbc as the default DBAPI. pymssql is also available:
# pyodbc
engine = create_engine("mssql+pyodbc://scott:tiger@mydsn")
# pymssql
engine = create_engine("mssql+pymssql://scott:tiger@hostname:port/dbname")More notes on connecting to SQL Server at Microsoft SQL Server.
SQLite¶
SQLite connects to file-based databases, using the Python built-in
module sqlite3 by default.
As SQLite connects to local files, the URL format is slightly different. The “file” portion of the URL is the filename of the database. For a relative file path, this requires three slashes:
# sqlite://<nohostname>/<path>
# where <path> is relative:
engine = create_engine("sqlite:///foo.db")And for an absolute file path, the three slashes are followed by the absolute path:
# Unix/Mac - 4 initial slashes in total
engine = create_engine("sqlite:////absolute/path/to/foo.db")
# Windows
engine = create_engine("sqlite:///C:\\path\\to\\foo.db")
# Windows alternative using raw string
engine = create_engine(r"sqlite:///C:\path\to\foo.db")To use a SQLite :memory: database, specify an empty URL:
engine = create_engine("sqlite://")More notes on connecting to SQLite at SQLite.
Others¶
See Dialects, the top-level page for all additional dialect documentation.
Engine Creation API¶
| Object Name | Description |
|---|---|
create_engine(url, **kwargs) |
Create a new |
create_mock_engine(url, executor, **kw) |
Create a “mock” engine used for echoing DDL. |
create_pool_from_url(url, **kwargs) |
Create a pool instance from the given url. |
engine_from_config(configuration[, prefix], **kwargs) |
Create a new Engine instance using a configuration dictionary. |
make_url(name_or_url) |
Given a string, produce a new URL instance. |
Represent the components of a URL used to connect to a database. |
- function sqlalchemy.create_engine(url: str | _url.URL, **kwargs: Any) Engine¶
Create a new
Engineinstance.The standard calling form is to send the URL as the first positional argument, usually a string that indicates database dialect and connection arguments:
engine = create_engine("postgresql+psycopg2://scott:tiger@localhost/test")
Note
Please review Database URLs for general guidelines in composing URL strings. In particular, special characters, such as those often part of passwords, must be URL encoded to be properly parsed.
Additional keyword arguments may then follow it which establish various options on the resulting
Engineand its underlyingDialectandPoolconstructs:engine = create_engine("mysql+mysqldb://scott:tiger@hostname/dbname", pool_recycle=3600, echo=True)
The string form of the URL is
dialect[+driver]://user:password@host/dbname[?key=value..], wheredialectis a database name such asmysql,oracle,postgresql, etc., anddriverthe name of a DBAPI, such aspsycopg2,pyodbc,cx_oracle, etc. Alternatively, the URL can be an instance ofURL.**kwargstakes a wide variety of options which are routed towards their appropriate components. Arguments may be specific to theEngine, the underlyingDialect, as well as thePool. Specific dialects also accept keyword arguments that are unique to that dialect. Here, we describe the parameters that are common to mostcreate_engine()usage.Once established, the newly resulting
Enginewill request a connection from the underlyingPoolonceEngine.connect()is called, or a method which depends on it such asEngine.execute()is invoked. ThePoolin turn will establish the first actual DBAPI connection when this request is received. Thecreate_engine()call itself does not establish any actual DBAPI connections directly.- Parameters:
connect_args¶ – a dictionary of options which will be passed directly to the DBAPI’s
connect()method as additional keyword arguments. See the example at Custom DBAPI connect() arguments / on-connect routines.creator¶ –
a callable which returns a DBAPI connection. This creation function will be passed to the underlying connection pool and will be used to create all new database connections. Usage of this function causes connection parameters specified in the URL argument to be bypassed.
This hook is not as flexible as the newer
DialectEvents.do_connect()hook which allows complete control over how a connection is made to the database, given the full set of URL arguments and state beforehand.See also
DialectEvents.do_connect()- event hook that allows full control over DBAPI connection mechanics.echo=False¶ –
if True, the Engine will log all statements as well as a
repr()of their parameter lists to the default log handler, which defaults tosys.stdoutfor output. If set to the string"debug", result rows will be printed to the standard output as well. Theechoattribute ofEnginecan be modified at any time to turn logging on and off; direct control of logging is also available using the standard Pythonloggingmodule.See also
Configuring Logging - further detail on how to configure logging.
echo_pool=False¶ –
if True, the connection pool will log informational output such as when connections are invalidated as well as when connections are recycled to the default log handler, which defaults to
sys.stdoutfor output. If set to the string"debug", the logging will include pool checkouts and checkins. Direct control of logging is also available using the standard Pythonloggingmodule.See also
Configuring Logging - further detail on how to configure logging.
empty_in_strategy¶ –
No longer used; SQLAlchemy now uses “empty set” behavior for IN in all cases.
Deprecated since version 1.4: The
create_engine.empty_in_strategykeyword is deprecated, and no longer has any effect. All IN expressions are now rendered using the “expanding parameter” strategy which renders a set of boundexpressions, or an “empty set” SELECT, at statement executiontime.enable_from_linting¶ –
defaults to True. Will emit a warning if a given SELECT statement is found to have un-linked FROM elements which would cause a cartesian product.
New in version 1.4.
execution_options¶ – Dictionary execution options which will be applied to all connections. See
Connection.execution_options()future¶ –
Use the 2.0 style
EngineandConnectionAPI.As of SQLAlchemy 2.0, this parameter is present for backwards compatibility only and must remain at its default value of
True.The
create_engine.futureparameter will be deprecated in a subsequent 2.x release and eventually removed.New in version 1.4.
Changed in version 2.0: All
Engineobjects are “future” style engines and there is no longer afuture=Falsemode of operation.hide_parameters¶ –
Boolean, when set to True, SQL statement parameters will not be displayed in INFO logging nor will they be formatted into the string representation of
StatementErrorobjects.New in version 1.3.8.
See also
Configuring Logging - further detail on how to configure logging.
implicit_returning=True¶ – Legacy parameter that may only be set to True. In SQLAlchemy 2.0, this parameter does nothing. In order to disable “implicit returning” for statements invoked by the ORM, configure this on a per-table basis using the
Table.implicit_returningparameter.insertmanyvalues_page_size¶ –
number of rows to format into an INSERT statement when the statement uses “insertmanyvalues” mode, which is a paged form of bulk insert that is used for many backends when using executemany execution typically in conjunction with RETURNING. Defaults to 1000, but may also be subject to dialect-specific limiting factors which may override this value on a per-statement basis.
New in version 2.0.
isolation_level¶ –
optional string name of an isolation level which will be set on all new connections unconditionally. Isolation levels are typically some subset of the string names
"SERIALIZABLE","REPEATABLE READ","READ COMMITTED","READ UNCOMMITTED"and"AUTOCOMMIT"based on backend.The
create_engine.isolation_levelparameter is in contrast to theConnection.execution_options.isolation_levelexecution option, which may be set on an individualConnection, as well as the same parameter passed toEngine.execution_options(), where it may be used to create multiple engines with different isolation levels that share a common connection pool and dialect.Changed in version 2.0: The
create_engine.isolation_levelparameter has been generalized to work on all dialects which support the concept of isolation level, and is provided as a more succinct, up front configuration switch in contrast to the execution option which is more of an ad-hoc programmatic option.json_deserializer¶ –
for dialects that support the
JSONdatatype, this is a Python callable that will convert a JSON string to a Python object. By default, the Pythonjson.loadsfunction is used.Changed in version 1.3.7: The SQLite dialect renamed this from
_json_deserializer.json_serializer¶ –
for dialects that support the
JSONdatatype, this is a Python callable that will render a given object as JSON. By default, the Pythonjson.dumpsfunction is used.Changed in version 1.3.7: The SQLite dialect renamed this from
_json_serializer.label_length=None¶ –
optional integer value which limits the size of dynamically generated column labels to that many characters. If less than 6, labels are generated as “_(counter)”. If
None, the value ofdialect.max_identifier_length, which may be affected via thecreate_engine.max_identifier_lengthparameter, is used instead. The value ofcreate_engine.label_lengthmay not be larger than that ofcreate_engine.max_identfier_length.See also
logging_name¶ –
String identifier which will be used within the “name” field of logging records generated within the “sqlalchemy.engine” logger. Defaults to a hexstring of the object’s id.
See also
Configuring Logging - further detail on how to configure logging.
max_identifier_length¶ –
integer; override the max_identifier_length determined by the dialect. if
Noneor zero, has no effect. This is the database’s configured maximum number of characters that may be used in a SQL identifier such as a table name, column name, or label name. All dialects determine this value automatically, however in the case of a new database version for which this value has changed but SQLAlchemy’s dialect has not been adjusted, the value may be passed here.New in version 1.3.9.
See also
max_overflow=10¶ – the number of connections to allow in connection pool “overflow”, that is connections that can be opened above and beyond the pool_size setting, which defaults to five. this is only used with
QueuePool.module=None¶ – reference to a Python module object (the module itself, not its string name). Specifies an alternate DBAPI module to be used by the engine’s dialect. Each sub-dialect references a specific DBAPI which will be imported before first connect. This parameter causes the import to be bypassed, and the given module to be used instead. Can be used for testing of DBAPIs as well as to inject “mock” DBAPI implementations into the
Engine.paramstyle=None¶ – The paramstyle to use when rendering bound parameters. This style defaults to the one recommended by the DBAPI itself, which is retrieved from the
.paramstyleattribute of the DBAPI. However, most DBAPIs accept more than one paramstyle, and in particular it may be desirable to change a “named” paramstyle into a “positional” one, or vice versa. When this attribute is passed, it should be one of the values"qmark","numeric","named","format"or"pyformat", and should correspond to a parameter style known to be supported by the DBAPI in use.pool=None¶ – an already-constructed instance of
Pool, such as aQueuePoolinstance. If non-None, this pool will be used directly as the underlying connection pool for the engine, bypassing whatever connection parameters are present in the URL argument. For information on constructing connection pools manually, see Connection Pooling.poolclass=None¶ – a
Poolsubclass, which will be used to create a connection pool instance using the connection parameters given in the URL. Note this differs frompoolin that you don’t actually instantiate the pool in this case, you just indicate what type of pool to be used.pool_logging_name¶ –
String identifier which will be used within the “name” field of logging records generated within the “sqlalchemy.pool” logger. Defaults to a hexstring of the object’s id.
See also
Configuring Logging - further detail on how to configure logging.
pool_pre_ping¶ –
boolean, if True will enable the connection pool “pre-ping” feature that tests connections for liveness upon each checkout.
New in version 1.2.
See also
pool_size=5¶ – the number of connections to keep open inside the connection pool. This used with
QueuePoolas well asSingletonThreadPool. WithQueuePool, apool_sizesetting of 0 indicates no limit; to disable pooling, setpoolclasstoNullPoolinstead.pool_recycle=-1¶ –
this setting causes the pool to recycle connections after the given number of seconds has passed. It defaults to -1, or no timeout. For example, setting to 3600 means connections will be recycled after one hour. Note that MySQL in particular will disconnect automatically if no activity is detected on a connection for eight hours (although this is configurable with the MySQLDB connection itself and the server configuration as well).
See also
pool_reset_on_return='rollback'¶ –
set the
Pool.reset_on_returnparameter of the underlyingPoolobject, which can be set to the values"rollback","commit", orNone.See also
pool_timeout=30¶ –
number of seconds to wait before giving up on getting a connection from the pool. This is only used with
QueuePool. This can be a float but is subject to the limitations of Python time functions which may not be reliable in the tens of milliseconds.pool_use_lifo=False¶ –
use LIFO (last-in-first-out) when retrieving connections from
QueuePoolinstead of FIFO (first-in-first-out). Using LIFO, a server-side timeout scheme can reduce the number of connections used during non- peak periods of use. When planning for server-side timeouts, ensure that a recycle or pre-ping strategy is in use to gracefully handle stale connections.New in version 1.3.
plugins¶ –
string list of plugin names to load. See
CreateEnginePluginfor background.New in version 1.2.3.
query_cache_size¶ –
size of the cache used to cache the SQL string form of queries. Set to zero to disable caching.
The cache is pruned of its least recently used items when its size reaches N * 1.5. Defaults to 500, meaning the cache will always store at least 500 SQL statements when filled, and will grow up to 750 items at which point it is pruned back down to 500 by removing the 250 least recently used items.
Caching is accomplished on a per-statement basis by generating a cache key that represents the statement’s structure, then generating string SQL for the current dialect only if that key is not present in the cache. All statements support caching, however some features such as an INSERT with a large set of parameters will intentionally bypass the cache. SQL logging will indicate statistics for each statement whether or not it were pull from the cache.
Note
some ORM functions related to unit-of-work persistence as well as some attribute loading strategies will make use of individual per-mapper caches outside of the main cache.
See also
New in version 1.4.
use_insertmanyvalues¶ –
True by default, use the “insertmanyvalues” execution style for INSERT..RETURNING statements by default.
New in version 2.0.
- function sqlalchemy.engine_from_config(configuration: Dict[str, Any], prefix: str = 'sqlalchemy.', **kwargs: Any) Engine¶
Create a new Engine instance using a configuration dictionary.
The dictionary is typically produced from a config file.
The keys of interest to
engine_from_config()should be prefixed, e.g.sqlalchemy.url,sqlalchemy.echo, etc. The ‘prefix’ argument indicates the prefix to be searched for. Each matching key (after the prefix is stripped) is treated as though it were the corresponding keyword argument to acreate_engine()call.The only required key is (assuming the default prefix)
sqlalchemy.url, which provides the database URL.A select set of keyword arguments will be “coerced” to their expected type based on string values. The set of arguments is extensible per-dialect using the
engine_config_typesaccessor.- Parameters:
configuration¶ – A dictionary (typically produced from a config file, but this is not a requirement). Items whose keys start with the value of ‘prefix’ will have that prefix stripped, and will then be passed to
create_engine().prefix¶ – Prefix to match and then strip from keys in ‘configuration’.
kwargs¶ – Each keyword argument to
engine_from_config()itself overrides the corresponding item taken from the ‘configuration’ dictionary. Keyword arguments should not be prefixed.
- function sqlalchemy.create_mock_engine(url: str | URL, executor: Any, **kw: Any) MockConnection¶
Create a “mock” engine used for echoing DDL.
This is a utility function used for debugging or storing the output of DDL sequences as generated by
MetaData.create_all()and related methods.The function accepts a URL which is used only to determine the kind of dialect to be used, as well as an “executor” callable function which will receive a SQL expression object and parameters, which can then be echoed or otherwise printed. The executor’s return value is not handled, nor does the engine allow regular string statements to be invoked, and is therefore only useful for DDL that is sent to the database without receiving any results.
E.g.:
from sqlalchemy import create_mock_engine def dump(sql, *multiparams, **params): print(sql.compile(dialect=engine.dialect)) engine = create_mock_engine('postgresql+psycopg2://', dump) metadata.create_all(engine, checkfirst=False)
- Parameters:
url¶ – A string URL which typically needs to contain only the database backend name.
executor¶ – a callable which receives the arguments
sql,*multiparamsand**params. Thesqlparameter is typically an instance ofExecutableDDLElement, which can then be compiled into a string usingExecutableDDLElement.compile().
New in version 1.4: - the
create_mock_engine()function replaces the previous “mock” engine strategy used withcreate_engine().
- function sqlalchemy.engine.make_url(name_or_url: str | URL) URL¶
Given a string, produce a new URL instance.
The format of the URL generally follows RFC-1738, with some exceptions, including that underscores, and not dashes or periods, are accepted within the “scheme” portion.
If a
URLobject is passed, it is returned as is.See also
- function sqlalchemy.create_pool_from_url(url: str | URL, **kwargs: Any) Pool¶
Create a pool instance from the given url.
If
poolclassis not provided the pool class used is selected using the dialect specified in the URL.The arguments passed to
create_pool_from_url()are identical to the pool argument passed to thecreate_engine()function.New in version 2.0.10.
- class sqlalchemy.engine.URL¶
Represent the components of a URL used to connect to a database.
URLs are typically constructed from a fully formatted URL string, where the
make_url()function is used internally by thecreate_engine()function in order to parse the URL string into its individual components, which are then used to construct a newURLobject. When parsing from a formatted URL string, the parsing format generally follows RFC-1738, with some exceptions.A
URLobject may also be produced directly, either by using themake_url()function with a fully formed URL string, or by using theURL.create()constructor in order to construct aURLprogrammatically given individual fields. The resultingURLobject may be passed directly tocreate_engine()in place of a string argument, which will bypass the usage ofmake_url()within the engine’s creation process.Changed in version 1.4: The
URLobject is now an immutable object. To create a URL, use themake_url()orURL.create()function / method. To modify aURL, use methods likeURL.set()andURL.update_query_dict()to return a newURLobject with modifications. See notes for this change at The URL object is now immutable.See also
URLcontains the following attributes:URL.drivername: database backend and driver name, such aspostgresql+psycopg2URL.username: username stringURL.password: password stringURL.host: string hostnameURL.port: integer port numberURL.database: string database nameURL.query: an immutable mapping representing the query string. contains strings for keys and either strings or tuples of strings for values.
Members
create(), database, difference_update_query(), drivername, get_backend_name(), get_dialect(), get_driver_name(), host, normalized_query, password, port, query, render_as_string(), set(), translate_connect_args(), update_query_dict(), update_query_pairs(), update_query_string(), username
Class signature
class
sqlalchemy.engine.URL(builtins.tuple)-
classmethod
sqlalchemy.engine.URL.create(drivername: str, username: str | None = None, password: str | None = None, host: str | None = None, port: int | None = None, database: str | None = None, query: Mapping[str, Sequence[str] | str] = {}) URL¶ Create a new
URLobject.See also
- Parameters:
drivername¶ – the name of the database backend. This name will correspond to a module in sqlalchemy/databases or a third party plug-in.
username¶ – The user name.
password¶ –
database password. Is typically a string, but may also be an object that can be stringified with
str().Note
The password string should not be URL encoded when passed as an argument to
URL.create(); the string should contain the password characters exactly as they would be typed.Note
A password-producing object will be stringified only once per
Engineobject. For dynamic password generation per connect, see Generating dynamic authentication tokens.host¶ – The name of the host.
port¶ – The port number.
database¶ – The database name.
query¶ – A dictionary of string keys to string values to be passed to the dialect and/or the DBAPI upon connect. To specify non-string parameters to a Python DBAPI directly, use the
create_engine.connect_argsparameter tocreate_engine(). See alsoURL.normalized_queryfor a dictionary that is consistently string->list of string.
- Returns:
new
URLobject.
New in version 1.4: The
URLobject is now an immutable named tuple. In addition, thequerydictionary is also immutable. To create a URL, use themake_url()orURL.create()function/ method. To modify aURL, use theURL.set()andURL.update_query()methods.
-
attribute
sqlalchemy.engine.URL.database: str | None¶ database name
-
method
sqlalchemy.engine.URL.difference_update_query(names: Iterable[str]) URL¶ Remove the given names from the
URL.querydictionary, returning the newURL.E.g.:
url = url.difference_update_query(['foo', 'bar'])
Equivalent to using
URL.set()as follows:url = url.set( query={ key: url.query[key] for key in set(url.query).difference(['foo', 'bar']) } )
New in version 1.4.
-
attribute
sqlalchemy.engine.URL.drivername: str¶ database backend and driver name, such as
postgresql+psycopg2
-
method
sqlalchemy.engine.URL.get_backend_name() str¶ Return the backend name.
This is the name that corresponds to the database backend in use, and is the portion of the
URL.drivernamethat is to the left of the plus sign.
-
method
sqlalchemy.engine.URL.get_dialect(_is_async: bool = False) Type[Dialect]¶ Return the SQLAlchemy
Dialectclass corresponding to this URL’s driver name.
-
method
sqlalchemy.engine.URL.get_driver_name() str¶ Return the backend name.
This is the name that corresponds to the DBAPI driver in use, and is the portion of the
URL.drivernamethat is to the right of the plus sign.If the
URL.drivernamedoes not include a plus sign, then the defaultDialectfor thisURLis imported in order to get the driver name.
-
attribute
sqlalchemy.engine.URL.host: str | None¶ hostname or IP number. May also be a data source name for some drivers.
-
attribute
sqlalchemy.engine.URL.normalized_query¶ Return the
URL.querydictionary with values normalized into sequences.As the
URL.querydictionary may contain either string values or sequences of string values to differentiate between parameters that are specified multiple times in the query string, code that needs to handle multiple parameters generically will wish to use this attribute so that all parameters present are presented as sequences. Inspiration is from Python’surllib.parse.parse_qsfunction. E.g.:>>> from sqlalchemy.engine import make_url >>> url = make_url("postgresql+psycopg2://user:pass@host/dbname?alt_host=host1&alt_host=host2&ssl_cipher=%2Fpath%2Fto%2Fcrt") >>> url.query immutabledict({'alt_host': ('host1', 'host2'), 'ssl_cipher': '/path/to/crt'}) >>> url.normalized_query immutabledict({'alt_host': ('host1', 'host2'), 'ssl_cipher': ('/path/to/crt',)})
-
attribute
sqlalchemy.engine.URL.password: str | None¶ password, which is normally a string but may also be any object that has a
__str__()method.
-
attribute
sqlalchemy.engine.URL.port: int | None¶ integer port number
-
attribute
sqlalchemy.engine.URL.query: immutabledict[str, Tuple[str, ...] | str]¶ an immutable mapping representing the query string. contains strings for keys and either strings or tuples of strings for values, e.g.:
>>> from sqlalchemy.engine import make_url >>> url = make_url("postgresql+psycopg2://user:pass@host/dbname?alt_host=host1&alt_host=host2&ssl_cipher=%2Fpath%2Fto%2Fcrt") >>> url.query immutabledict({'alt_host': ('host1', 'host2'), 'ssl_cipher': '/path/to/crt'}) To create a mutable copy of this mapping, use the ``dict`` constructor:: mutable_query_opts = dict(url.query)
See also
URL.normalized_query- normalizes all values into sequences for consistent processingMethods for altering the contents of
URL.query:
-
method
sqlalchemy.engine.URL.render_as_string(hide_password: bool = True) str¶ Render this
URLobject as a string.This method is used when the
__str__()or__repr__()methods are used. The method directly includes additional options.- Parameters:
hide_password¶ – Defaults to True. The password is not shown in the string unless this is set to False.
-
method
sqlalchemy.engine.URL.set(drivername: str | None = None, username: str | None = None, password: str | None = None, host: str | None = None, port: int | None = None, database: str | None = None, query: Mapping[str, Sequence[str] | str] | None = None) URL¶ return a new
URLobject with modifications.Values are used if they are non-None. To set a value to
Noneexplicitly, use theURL._replace()method adapted fromnamedtuple.- Parameters:
- Returns:
new
URLobject.
New in version 1.4.
See also
-
method
sqlalchemy.engine.URL.translate_connect_args(names: List[str] | None = None, **kw: Any) Dict[str, Any]¶ Translate url attributes into a dictionary of connection arguments.
Returns attributes of this url (host, database, username, password, port) as a plain dictionary. The attribute names are used as the keys by default. Unset or false attributes are omitted from the final dictionary.
-
method
sqlalchemy.engine.URL.update_query_dict(query_parameters: Mapping[str, str | List[str]], append: bool = False) URL¶ Return a new
URLobject with theURL.queryparameter dictionary updated by the given dictionary.The dictionary typically contains string keys and string values. In order to represent a query parameter that is expressed multiple times, pass a sequence of string values.
E.g.:
>>> from sqlalchemy.engine import make_url >>> url = make_url("postgresql+psycopg2://user:pass@host/dbname") >>> url = url.update_query_dict({"alt_host": ["host1", "host2"], "ssl_cipher": "/path/to/crt"}) >>> str(url) 'postgresql+psycopg2://user:pass@host/dbname?alt_host=host1&alt_host=host2&ssl_cipher=%2Fpath%2Fto%2Fcrt'
- Parameters:
query_parameters¶ – A dictionary with string keys and values that are either strings, or sequences of strings.
append¶ – if True, parameters in the existing query string will not be removed; new parameters will be in addition to those present. If left at its default of False, keys present in the given query parameters will replace those of the existing query string.
New in version 1.4.
-
method
sqlalchemy.engine.URL.update_query_pairs(key_value_pairs: Iterable[Tuple[str, str | List[str]]], append: bool = False) URL¶ Return a new
URLobject with theURL.queryparameter dictionary updated by the given sequence of key/value pairsE.g.:
>>> from sqlalchemy.engine import make_url >>> url = make_url("postgresql+psycopg2://user:pass@host/dbname") >>> url = url.update_query_pairs([("alt_host", "host1"), ("alt_host", "host2"), ("ssl_cipher", "/path/to/crt")]) >>> str(url) 'postgresql+psycopg2://user:pass@host/dbname?alt_host=host1&alt_host=host2&ssl_cipher=%2Fpath%2Fto%2Fcrt'
- Parameters:
key_value_pairs¶ – A sequence of tuples containing two strings each.
append¶ – if True, parameters in the existing query string will not be removed; new parameters will be in addition to those present. If left at its default of False, keys present in the given query parameters will replace those of the existing query string.
New in version 1.4.
-
method
sqlalchemy.engine.URL.update_query_string(query_string: str, append: bool = False) URL¶ Return a new
URLobject with theURL.queryparameter dictionary updated by the given query string.E.g.:
>>> from sqlalchemy.engine import make_url >>> url = make_url("postgresql+psycopg2://user:pass@host/dbname") >>> url = url.update_query_string("alt_host=host1&alt_host=host2&ssl_cipher=%2Fpath%2Fto%2Fcrt") >>> str(url) 'postgresql+psycopg2://user:pass@host/dbname?alt_host=host1&alt_host=host2&ssl_cipher=%2Fpath%2Fto%2Fcrt'
- Parameters:
query_string¶ – a URL escaped query string, not including the question mark.
append¶ – if True, parameters in the existing query string will not be removed; new parameters will be in addition to those present. If left at its default of False, keys present in the given query parameters will replace those of the existing query string.
New in version 1.4.
-
attribute
sqlalchemy.engine.URL.username: str | None¶ username string
Pooling¶
The Engine will ask the connection pool for a
connection when the connect() or execute() methods are called. The
default connection pool, QueuePool, will open connections to the
database on an as-needed basis. As concurrent statements are executed,
QueuePool will grow its pool of connections to a
default size of five, and will allow a default “overflow” of ten. Since the
Engine is essentially “home base” for the
connection pool, it follows that you should keep a single
Engine per database established within an
application, rather than creating a new one for each connection.
Note
QueuePool is not used by default for SQLite engines. See
SQLite for details on SQLite connection pool usage.
For more information on connection pooling, see Connection Pooling.
Custom DBAPI connect() arguments / on-connect routines¶
For cases where special connection methods are needed, in the vast majority
of cases, it is most appropriate to use one of several hooks at the
create_engine() level in order to customize this process. These
are described in the following sub-sections.
Special Keyword Arguments Passed to dbapi.connect()¶
All Python DBAPIs accept additional arguments beyond the basics of connecting. Common parameters include those to specify character set encodings and timeout values; more complex data includes special DBAPI constants and objects and SSL sub-parameters. There are two rudimentary means of passing these arguments without complexity.
Add Parameters to the URL Query string¶
Simple string values, as well as some numeric values and boolean flags, may be
often specified in the query string of the URL directly. A common example of
this is DBAPIs that accept an argument encoding for character encodings,
such as most MySQL DBAPIs:
engine = create_engine("mysql+pymysql://user:pass@host/test?charset=utf8mb4")The advantage of using the query string is that additional DBAPI options may be specified in configuration files in a manner that’s portable to the DBAPI specified in the URL. The specific parameters passed through at this level vary by SQLAlchemy dialect. Some dialects pass all arguments through as strings, while others will parse for specific datatypes and move parameters to different places, such as into driver-level DSNs and connect strings. As per-dialect behavior in this area currently varies, the dialect documentation should be consulted for the specific dialect in use to see if particular parameters are supported at this level.
Tip
A general technique to display the exact arguments passed to the DBAPI
for a given URL may be performed using the Dialect.create_connect_args()
method directly as follows:
>>> from sqlalchemy import create_engine
>>> engine = create_engine(
... "mysql+pymysql://some_user:some_pass@some_host/test?charset=utf8mb4"
... )
>>> args, kwargs = engine.dialect.create_connect_args(engine.url)
>>> args, kwargs
([], {'host': 'some_host', 'database': 'test', 'user': 'some_user', 'password': 'some_pass', 'charset': 'utf8mb4', 'client_flag': 2})The above args, kwargs pair is normally passed to the DBAPI as
dbapi.connect(*args, **kwargs).
Use the connect_args dictionary parameter¶
A more general system of passing any parameter to the dbapi.connect()
function that is guaranteed to pass all parameters at all times is the
create_engine.connect_args dictionary parameter. This may be
used for parameters that are otherwise not handled by the dialect when added to
the query string, as well as when special sub-structures or objects must be
passed to the DBAPI. Sometimes it’s just that a particular flag must be sent as
the True symbol and the SQLAlchemy dialect is not aware of this keyword
argument to coerce it from its string form as presented in the URL. Below
illustrates the use of a psycopg2 “connection factory” that replaces the
underlying implementation the connection:
engine = create_engine(
"postgresql+psycopg2://user:pass@hostname/dbname",
connect_args={"connection_factory": MyConnectionFactory},
)Another example is the pyodbc “timeout” parameter:
engine = create_engine(
"mssql+pyodbc://user:pass@sqlsrvr?driver=ODBC+Driver+13+for+SQL+Server",
connect_args={"timeout": 30},
)The above example also illustrates that both URL “query string” parameters as
well as create_engine.connect_args may be used at the same
time; in the case of pyodbc, the “driver” keyword has special meaning
within the URL.
Controlling how parameters are passed to the DBAPI connect() function¶
Beyond manipulating the parameters passed to connect(), we can further
customize how the DBAPI connect() function itself is called using the
DialectEvents.do_connect() event hook. This hook is passed the full
*args, **kwargs that the dialect would send to connect(). These
collections can then be modified in place to alter how they are used:
from sqlalchemy import event
engine = create_engine("postgresql+psycopg2://user:pass@hostname/dbname")
@event.listens_for(engine, "do_connect")
def receive_do_connect(dialect, conn_rec, cargs, cparams):
cparams["connection_factory"] = MyConnectionFactoryGenerating dynamic authentication tokens¶
DialectEvents.do_connect() is also an ideal way to dynamically
insert an authentication token that might change over the lifespan of an
Engine. For example, if the token gets generated by
get_authentication_token() and passed to the DBAPI in a token
parameter, this could be implemented as:
from sqlalchemy import event
engine = create_engine("postgresql+psycopg2://user@hostname/dbname")
@event.listens_for(engine, "do_connect")
def provide_token(dialect, conn_rec, cargs, cparams):
cparams["token"] = get_authentication_token()See also
Connecting to databases with access tokens - a more concrete example involving SQL Server
Modifying the DBAPI connection after connect, or running commands after connect¶
For a DBAPI connection that SQLAlchemy creates without issue, but where we
would like to modify the completed connection before it’s actually used, such
as for setting special flags or running certain commands, the
PoolEvents.connect() event hook is the most appropriate hook. This
hook is called for every new connection created, before it is used by
SQLAlchemy:
from sqlalchemy import event
engine = create_engine("postgresql+psycopg2://user:pass@hostname/dbname")
@event.listens_for(engine, "connect")
def connect(dbapi_connection, connection_record):
cursor_obj = dbapi_connection.cursor()
cursor_obj.execute("SET some session variables")
cursor_obj.close()Fully Replacing the DBAPI connect() function¶
Finally, the DialectEvents.do_connect() event hook can also allow us to take
over the connection process entirely by establishing the connection
and returning it:
from sqlalchemy import event
engine = create_engine("postgresql+psycopg2://user:pass@hostname/dbname")
@event.listens_for(engine, "do_connect")
def receive_do_connect(dialect, conn_rec, cargs, cparams):
# return the new DBAPI connection with whatever we'd like to
# do
return psycopg2.connect(*cargs, **cparams)The DialectEvents.do_connect() hook supersedes the previous
create_engine.creator hook, which remains available.
DialectEvents.do_connect() has the distinct advantage that the
complete arguments parsed from the URL are also passed to the user-defined
function which is not the case with create_engine.creator.
Configuring Logging¶
Python’s standard logging module is used to
implement informational and debug log output with SQLAlchemy. This allows
SQLAlchemy’s logging to integrate in a standard way with other applications
and libraries. There are also two parameters
create_engine.echo and create_engine.echo_pool
present on create_engine() which allow immediate logging to sys.stdout
for the purposes of local development; these parameters ultimately interact
with the regular Python loggers described below.
This section assumes familiarity with the above linked logging module. All
logging performed by SQLAlchemy exists underneath the sqlalchemy
namespace, as used by logging.getLogger('sqlalchemy'). When logging has
been configured (i.e. such as via logging.basicConfig()), the general
namespace of SA loggers that can be turned on is as follows:
sqlalchemy.engine- controls SQL echoing. Set tologging.INFOfor SQL query output,logging.DEBUGfor query + result set output. These settings are equivalent toecho=Trueandecho="debug"oncreate_engine.echo, respectively.sqlalchemy.pool- controls connection pool logging. Set tologging.INFOto log connection invalidation and recycle events; set tologging.DEBUGto additionally log all pool checkins and checkouts. These settings are equivalent topool_echo=Trueandpool_echo="debug"oncreate_engine.echo_pool, respectively.sqlalchemy.dialects- controls custom logging for SQL dialects, to the extent that logging is used within specific dialects, which is generally minimal.sqlalchemy.orm- controls logging of various ORM functions to the extent that logging is used within the ORM, which is generally minimal. Set tologging.INFOto log some top-level information on mapper configurations.
For example, to log SQL queries using Python logging instead of the
echo=True flag:
import logging
logging.basicConfig()
logging.getLogger("sqlalchemy.engine").setLevel(logging.INFO)By default, the log level is set to logging.WARN within the entire
sqlalchemy namespace so that no log operations occur, even within an
application that has logging enabled otherwise.
Note
The SQLAlchemy Engine conserves Python function call
overhead by only emitting log statements when the current logging level is
detected as logging.INFO or logging.DEBUG. It only checks this
level when a new connection is procured from the connection pool. Therefore
when changing the logging configuration for an already-running application,
any Connection that’s currently active, or more commonly a
Session object that’s active in a transaction, won’t
log any SQL according to the new configuration until a new
Connection is procured (in the case of
Session, this is after the current transaction ends
and a new one begins).
More on the Echo Flag¶
As mentioned previously, the create_engine.echo and create_engine.echo_pool
parameters are a shortcut to immediate logging to sys.stdout:
>>> from sqlalchemy import create_engine, text
>>> e = create_engine("sqlite://", echo=True, echo_pool="debug")
>>> with e.connect() as conn:
... print(conn.scalar(text("select 'hi'")))
2020-10-24 12:54:57,701 DEBUG sqlalchemy.pool.impl.SingletonThreadPool Created new connection <sqlite3.Connection object at 0x7f287819ac60>
2020-10-24 12:54:57,701 DEBUG sqlalchemy.pool.impl.SingletonThreadPool Connection <sqlite3.Connection object at 0x7f287819ac60> checked out from pool
2020-10-24 12:54:57,702 INFO sqlalchemy.engine.Engine select 'hi'
2020-10-24 12:54:57,702 INFO sqlalchemy.engine.Engine ()
hi
2020-10-24 12:54:57,703 DEBUG sqlalchemy.pool.impl.SingletonThreadPool Connection <sqlite3.Connection object at 0x7f287819ac60> being returned to pool
2020-10-24 12:54:57,704 DEBUG sqlalchemy.pool.impl.SingletonThreadPool Connection <sqlite3.Connection object at 0x7f287819ac60> rollback-on-returnUse of these flags is roughly equivalent to:
import logging
logging.basicConfig()
logging.getLogger("sqlalchemy.engine").setLevel(logging.INFO)
logging.getLogger("sqlalchemy.pool").setLevel(logging.DEBUG)It’s important to note that these two flags work independently of any
existing logging configuration, and will make use of logging.basicConfig()
unconditionally. This has the effect of being configured in addition to
any existing logger configurations. Therefore, when configuring logging
explicitly, ensure all echo flags are set to False at all times, to avoid
getting duplicate log lines.
Setting the Logging Name¶
The logger name of instance such as an Engine or
Pool defaults to using a truncated hex identifier
string. To set this to a specific name, use the
create_engine.logging_name and
create_engine.pool_logging_name with
sqlalchemy.create_engine(); the name will be appended to the logging name
sqlalchemy.engine.Engine:
>>> import logging
>>> from sqlalchemy import create_engine
>>> from sqlalchemy import text
>>> logging.basicConfig()
>>> logging.getLogger("sqlalchemy.engine.Engine.myengine").setLevel(logging.INFO)
>>> e = create_engine("sqlite://", logging_name="myengine")
>>> with e.connect() as conn:
... conn.execute(text("select 'hi'"))
2020-10-24 12:47:04,291 INFO sqlalchemy.engine.Engine.myengine select 'hi'
2020-10-24 12:47:04,292 INFO sqlalchemy.engine.Engine.myengine ()Tip
The create_engine.logging_name and
create_engine.pool_logging_name parameters may also be used in
conjunction with create_engine.echo and
create_engine.echo_pool. However, an unavoidable double logging
condition will occur if other engines are created with echo flags set to True
and no logging name. This is because a handler will be added automatically
for sqlalchemy.engine.Engine which will log messages both for the name-less
engine as well as engines with logging names. For example:
from sqlalchemy import create_engine, text
e1 = create_engine("sqlite://", echo=True, logging_name="myname")
with e1.begin() as conn:
conn.execute(text("SELECT 1"))
e2 = create_engine("sqlite://", echo=True)
with e2.begin() as conn:
conn.execute(text("SELECT 2"))
with e1.begin() as conn:
conn.execute(text("SELECT 3"))The above scenario will double log SELECT 3. To resolve, ensure
all engines have a logging_name set, or use explicit logger / handler
setup without using create_engine.echo and
create_engine.echo_pool.
Setting Per-Connection / Sub-Engine Tokens¶
New in version 1.4.0b2.
While the logging name is appropriate to establish on an
Engine object that is long lived, it’s not flexible enough
to accommodate for an arbitrarily large list of names, for the case of
tracking individual connections and/or transactions in log messages.
For this use case, the log message itself generated by the
Connection and Result objects may be
augmented with additional tokens such as transaction or request identifiers.
The Connection.execution_options.logging_token parameter
accepts a string argument that may be used to establish per-connection tracking
tokens:
>>> from sqlalchemy import create_engine
>>> e = create_engine("sqlite://", echo="debug")
>>> with e.connect().execution_options(logging_token="track1") as conn:
... conn.execute(text("select 1")).all()
2021-02-03 11:48:45,754 INFO sqlalchemy.engine.Engine [track1] select 1
2021-02-03 11:48:45,754 INFO sqlalchemy.engine.Engine [track1] [raw sql] ()
2021-02-03 11:48:45,754 DEBUG sqlalchemy.engine.Engine [track1] Col ('1',)
2021-02-03 11:48:45,755 DEBUG sqlalchemy.engine.Engine [track1] Row (1,)The Connection.execution_options.logging_token parameter
may also be established on engines or sub-engines via
create_engine.execution_options or Engine.execution_options().
This may be useful to apply different logging tokens to different components
of an application without creating new engines:
>>> from sqlalchemy import create_engine
>>> e = create_engine("sqlite://", echo="debug")
>>> e1 = e.execution_options(logging_token="track1")
>>> e2 = e.execution_options(logging_token="track2")
>>> with e1.connect() as conn:
... conn.execute(text("select 1")).all()
2021-02-03 11:51:08,960 INFO sqlalchemy.engine.Engine [track1] select 1
2021-02-03 11:51:08,960 INFO sqlalchemy.engine.Engine [track1] [raw sql] ()
2021-02-03 11:51:08,960 DEBUG sqlalchemy.engine.Engine [track1] Col ('1',)
2021-02-03 11:51:08,961 DEBUG sqlalchemy.engine.Engine [track1] Row (1,)
>>> with e2.connect() as conn:
... conn.execute(text("select 2")).all()
2021-02-03 11:52:05,518 INFO sqlalchemy.engine.Engine [track2] Select 1
2021-02-03 11:52:05,519 INFO sqlalchemy.engine.Engine [track2] [raw sql] ()
2021-02-03 11:52:05,520 DEBUG sqlalchemy.engine.Engine [track2] Col ('1',)
2021-02-03 11:52:05,520 DEBUG sqlalchemy.engine.Engine [track2] Row (1,)Hiding Parameters¶
The logging emitted by Engine also indicates an excerpt
of the SQL parameters that are present for a particular statement. To prevent
these parameters from being logged for privacy purposes, enable the
create_engine.hide_parameters flag:
>>> e = create_engine("sqlite://", echo=True, hide_parameters=True)
>>> with e.connect() as conn:
... conn.execute(text("select :some_private_name"), {"some_private_name": "pii"})
2020-10-24 12:48:32,808 INFO sqlalchemy.engine.Engine select ?
2020-10-24 12:48:32,808 INFO sqlalchemy.engine.Engine [SQL parameters hidden due to hide_parameters=True]